Anthropic Interpretability and the Pope
You keep hearing that advanced AI systems are getting smarter, faster, and harder to understand. That last part matters most. If the people building frontier models cannot explain why those systems make certain choices, every promise about safety starts to sound thin. The Wired report on Anthropic, Christopher Olah, and a papal meeting lands right on that pressure point. Anthropic interpretability is no side project. It is part science, part public argument, and part power move in the race to define what responsible AI should look like. Why bring those ideas to the Vatican? Because AI governance is no longer just a technical debate. It is becoming a moral and political one, and companies want influential institutions on the record before the stakes get even higher.
What stands out
- Anthropic is pushing interpretability as a core safety idea, not a public relations add-on.
- Christopher Olah has become one of the clearest public faces for understanding how large models work internally.
- The Vatican angle shows that AI firms are now courting moral authority, not just regulators and researchers.
- You should read this as a signal about future AI policy fights over transparency, accountability, and trust.
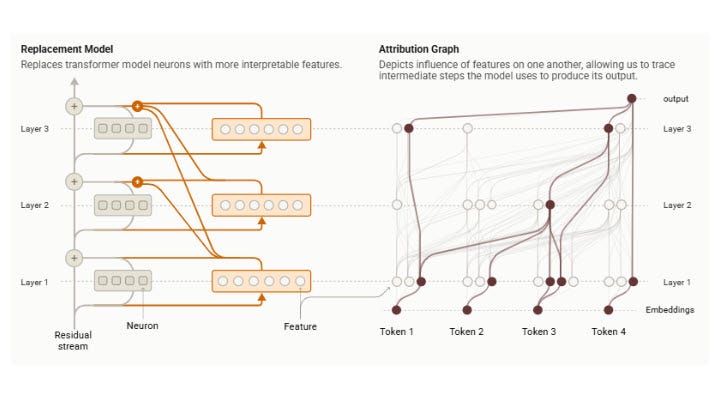
Why anthropic interpretability matters now
Look, most AI companies still sell performance first. Better benchmarks. Better coding. Better agents. But safety claims are harder to test from the outside. That is why interpretability matters. It aims to reveal what is happening inside a model, including patterns, features, and internal circuits that shape outputs.
Anthropic has put more weight on this than many rivals. The company has published work on mechanistic interpretability and model auditing, and it often frames that work as a path toward spotting deception, harmful reasoning, or unstable behavior before deployment. That is the theory, anyway.
And the theory is still being tested.
Here is the core tension. Large language models can produce useful answers at scale, but they remain opaque in many ways. Researchers can measure outputs, stress-test behaviors, and compare benchmark scores. Those are useful tools. They still do not fully explain why a model arrived at a given answer, or whether similar hidden processes might produce bad outcomes in another context.
“If you cannot inspect the engine, you are driving on trust alone.”
That is not a quote from the Wired story. It is the plain reality of frontier AI right now.
Who is Christopher Olah, and why does Wired focus on him?
Christopher Olah has long been one of the most influential voices in interpretability research. Before Anthropic, he helped shape the field through work tied to OpenAI and Distill, a publication known for unusually clear technical explanations. In AI circles, Olah is associated with the idea that neural networks are not black boxes by destiny. They are hard to study, yes, but not impossible to inspect.
Wired’s focus makes sense. Olah is not just another staff researcher. He represents a vision of AI safety that says understanding model internals is non-negotiable if companies want serious credibility. That puts him in contrast with the louder camp that tends to treat scaling and product release as the main event, while safety work follows behind.
Honestly, this is why the Vatican meeting matters symbolically. You do not send a pure lobbyist if your goal is to frame AI as a moral issue. You send someone whose work suggests that technical transparency and ethical responsibility are linked.
Why take anthropic interpretability to the Vatican?
At first glance, it sounds odd. A frontier AI company, a star interpretability researcher, and the pope? But step back and it tracks. The Catholic Church has spent years weighing in on AI ethics, including questions around human dignity, labor, surveillance, and automated decision-making. The Vatican is not a regulator, but it has global reach and a serious voice in moral debates.
So what does Anthropic gain?
- Moral framing. The company can position AI safety as a human issue, not just an engineering issue.
- Institutional legitimacy. Alignment talk often sounds abstract. Tying it to trusted institutions makes it feel less like internal industry jargon.
- Policy influence. Ethical language often travels into policy papers, regulatory hearings, and international forums.
- Brand separation. Anthropic can further distinguish itself from rivals by saying, in effect, we are the company trying to understand the machine before scaling it everywhere.
Think of it like architecture. Anyone can brag about how fast they built the tower. The tougher question is whether anyone inspected the load-bearing walls.
What the Wired story signals about the next phase of AI politics
The big story here is not religion. It is coalition building. AI firms now know that technical papers alone will not settle public trust. Regulators want evidence. Citizens want accountability. Labor groups want protections. Religious and civic institutions want a voice in how these systems shape human life.
That broadening circle changes the debate.
For years, the dominant AI script was simple: build, launch, apologize later if needed. That script is weaker now, especially after waves of concern around misinformation, bias, copyright fights, deepfakes, and concentration of power. Anthropic appears to be betting that the company best able to talk about internal model understanding will hold a stronger hand as regulation gets more specific.
Will interpretability actually deliver that level of assurance? Good question. The field has made real progress, but it is still early. Researchers can identify some model features and behaviors, yet modern systems remain wildly complex. Reading a few internal traces is not the same as having a full safety case.
How much of anthropic interpretability is science, and how much is strategy?
Both. That is the honest answer.
Anthropic does have real technical depth here. Its researchers have produced notable work on understanding model representations and internal behavior. The broader interpretability field also includes serious contributions from groups across academia and industry. This is not empty branding.
But companies do not promote one area this hard unless it also serves a strategic purpose. Anthropic needs a durable identity in a market dominated by giant compute budgets, aggressive product launches, and constant benchmark theater. Interpretability gives it one. It says the company is trying to answer a harder question than “what can the model do?” It asks, “what is the model doing under the hood?”
That pitch is smart, especially if lawmakers start requiring clearer safety documentation, independent audits, or deployment controls for advanced models.
What you should watch next
If you want to judge whether this is substance or image management, watch for a few concrete signals:
- More technical papers with practical use. Can interpretability findings actually improve evaluations, red-teaming, or model restrictions?
- Independent validation. Do outside researchers confirm that these methods reveal meaningful model behavior?
- Policy uptake. Do regulators and standards groups start treating interpretability as part of AI safety expectations?
- Product impact. Does Anthropic slow, change, or block model features because interpretability work found something risky?
That last point matters most. If interpretability never changes what gets shipped, then it risks becoming a very polished story told to elites in nice rooms (including Vatican ones).
Where this leaves the rest of the AI industry
Rivals should pay attention. If Anthropic succeeds in tying anthropic interpretability to credible safety leadership, competitors may have to respond with stronger transparency efforts of their own. That could mean more investment in model auditing, better documentation, or new disclosure norms around system behavior and limits.
But there is also a risk. Interpretability can be oversold. Companies may imply that partial visibility into a model equals true control. It does not. A few strong demos do not solve the problem of governing systems that learn diffuse patterns from giant datasets and can behave unpredictably across contexts.
Still, I would rather see firms compete on explainability than on speed alone. That is at least a fight worth having.
The next real test
The Wired piece works because it captures a shift that many people still miss. AI companies are no longer speaking only to engineers, venture capitalists, and Washington staffers. They are trying to shape the moral vocabulary around these systems before stricter rules arrive.
If Anthropic wants that argument to stick, it will need to show that anthropic interpretability can do more than impress policymakers and religious leaders. It needs to change how frontier models are built, evaluated, and limited in practice. If that happens, Olah’s meeting at the Vatican may look less quirky in hindsight and more like an early sign of where the real AI power struggle was headed. If it does not, then what was all this for?


