Databricks AI Power Bill Cut: What 1000x Means
AI teams are hitting a hard wall. Training costs are high, inference bills keep climbing, and every new product pitch seems to assume you can throw more GPUs at the problem. That is why the claim from Databricks’ former AI chief, that he can cut the AI power bill by 1000x, matters right now. If even part of that holds up, it changes the economics of model training and deployment in a way most vendors are still pretending to understand.
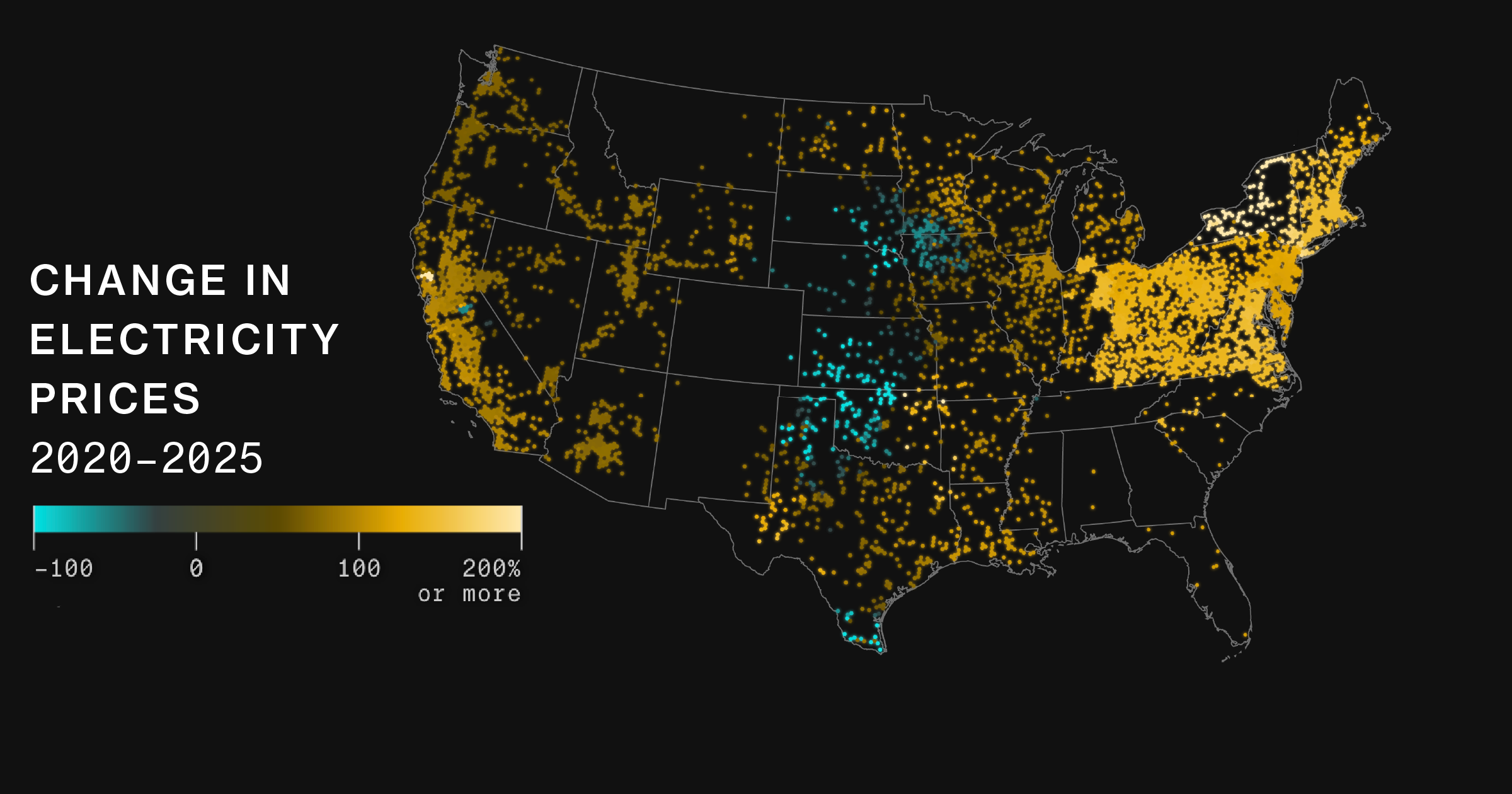
Look past the hype and the real issue is simple. Companies do not just want smarter models. They want models they can afford to run every day, at scale, without watching energy and cloud spend turn ugly. Can AI keep growing if each jump in capability drags a heavier electricity bill behind it? That is the question, and it is not academic.
What stands out
- Energy cost is now a product issue, not just an infrastructure line item.
- A 1000x cut would matter most in inference, where models serve millions of requests.
- Any real savings will likely come from smaller models, better routing, and tighter hardware use.
- Claims like this need proof on real workloads, not polished demos.
Why the AI power bill is getting so much attention
For years, AI teams talked about compute in vague terms. That changed once foundation models got bigger, usage grew, and energy bills became impossible to hide. Training a frontier model can burn huge amounts of power, but inference is where the pain often lands every day, because every prompt, search, or agent step has a cost.
Databricks sits close to that pressure point. Its customers want analytics, data pipelines, and AI features that run inside real budgets. So when a former AI chief says he can cut the AI power bill by orders of magnitude, the claim is aimed straight at a market that is tired of paying premium prices for marginal gains.
“If the economics do not improve, AI stays impressive and stays niche.”
How could a 1000x cut actually happen?
Not by magic. A cut that large would need multiple changes working together, and some of them are already familiar to anyone following model efficiency.
- Use smaller models for more tasks. Most jobs do not need the largest model in the room. Routing simple prompts to lighter models can slash compute use.
- Reduce wasted tokens. Better prompting, shorter context windows, and cleaner retrieval can trim useless output and input load.
- Improve batching and scheduling. A model farm is a lot like a busy kitchen. If orders pile up one by one, everything slows down. If you batch the right jobs, throughput jumps.
- Run on more efficient hardware. GPU choice, memory use, and quantization all affect how much power each request burns.
- Architect for the task. Sometimes a narrow model, a rules layer, or a retrieval system beats a giant general model (and costs far less).
That is the practical playbook. It is not sexy, but it is how you get real savings. And it is also why claims of a 1000x drop need a careful read. A lab benchmark is one thing. A production workload with messy traffic, latency targets, and compliance rules is something else entirely.
What the AI power bill really includes
People often think power cost means the electric bill for a data center. That is too narrow. The full cost stack includes chips, cooling, cloud pricing, engineering time, uptime requirements, and the fact that inefficient systems force you to buy more capacity than you should need.
For many teams, energy is a proxy for waste. If a model burns fewer watts per useful answer, it usually also improves GPU utilization and lowers cloud spend. That is why energy efficiency has become a business metric, not just an environmental one. The cleaner the pipeline, the less money leaks out of the system.
Where the savings may be hardest to prove
Training is easier to benchmark than inference. You can measure a run, count the chips, and estimate energy use. Inference is messier. Traffic changes by the hour, prompts vary in length, and product teams keep adding features that quietly increase compute use.
That makes exact savings hard to compare across companies. One team may run a highly tuned internal assistant. Another may serve external customers with spikes, retries, and long context windows. Same model family. Very different power profile.
What you should ask before believing the claim
Big efficiency claims are common in AI, but you should treat them like any other technical pitch. Ask for the workload, the baseline, and the measurement method. Ask whether the improvement applies to training, inference, or both. Ask if the result holds under real traffic, not a neat demo set.
That is the part many vendors skip.
Also ask what tradeoffs show up. Does latency improve or worsen? Does quality hold steady? Does the system need new tooling, new hardware, or a rewrite of existing pipelines? A lower power bill that breaks product performance is not a win. It is just a different bill.
What this means for AI buyers
If this line of thinking proves out, AI procurement will change fast. Teams will stop asking only how accurate a model is and start asking how much power it uses per task. FinOps and platform teams will get pulled into AI decisions much earlier, because the bill will no longer be hidden in a single cloud line item.
For buyers, the smart move is to pressure vendors for efficiency data now. Compare tokens per useful answer. Compare latency under load. Compare cost per workflow, not just benchmark scores. That is where the real economics live.
And if a vendor cannot explain those numbers in plain language, why should you trust the pitch?
Where this goes next
The AI market has spent years rewarding scale for its own sake. That phase is ending. The next phase will reward systems that do more with less, especially if the savings are large enough to change buying behavior. A 1000x power cut is a bold claim, maybe even a stretch. But the direction is right, and the pressure is real.
Watch for the companies that can prove efficiency on live workloads. They will shape the next wave of AI infrastructure. The rest will keep selling bigger models into a market that is learning to ask a very uncomfortable question: how much power does this answer really need?