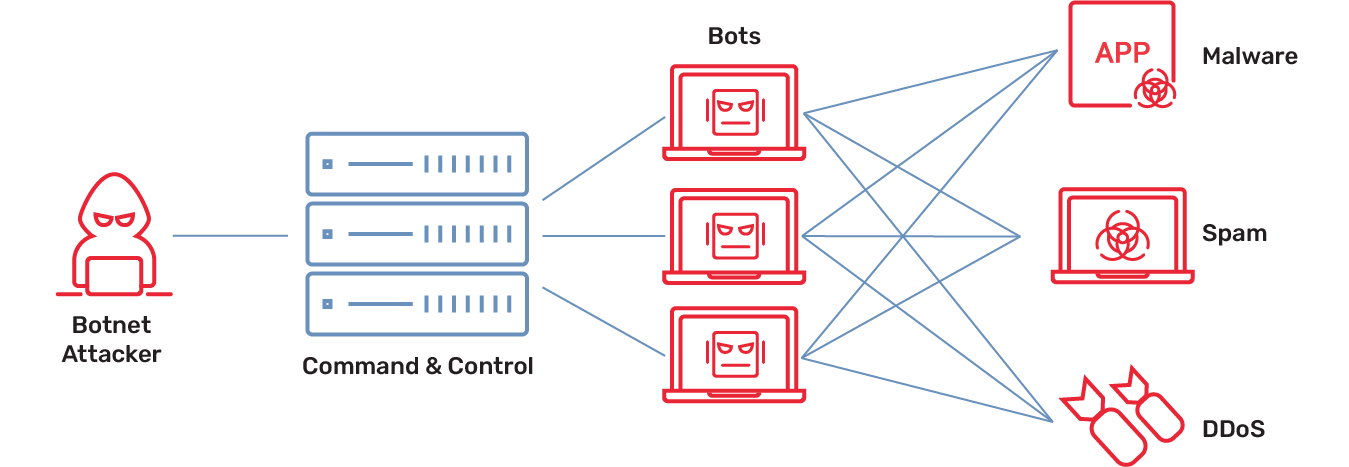
Open Source AI vs Closed Models: What Meta’s Choices Signal
You want to ship faster with dependable models, yet the ground keeps moving. Open source AI promised cheap iteration and transparency, but Meta’s swing between releasing Llama weights and gating newer variants shows how fragile that bargain can be. Your roadmap depends on whether open source AI remains available or slides into a walled garden. The stakes are financial and strategic: do you build on community stacks or rent access from a single vendor? Here’s how to read Meta’s latest moves and set a plan that survives either outcome.
What matters now
- Meta’s licensing tweaks hint at a tighter grip on high-quality weights.
- Closed APIs reduce operational hassle but add lock-in risk.
- Open source AI still cuts inference costs if you manage infra well.
- Evaluate governance, not just benchmarks, before you bet your stack.
Open Source AI reality check
Meta’s early Llama drops fueled a wave of community fine-tunes and cheap deployments. The newer releases arrive with more restrictions, signaling that full openness was never guaranteed. Who gains if models stay closed?
Control of model weights shapes who captures value in the next wave of AI products.
Look at it like cooking: you can buy a finished meal through an API or get the recipe and cook at home. The first is fast, the second gives you control over ingredients, budget, and flavor. If the recipe disappears, your kitchen loses its edge.
Silence on model weights is its own message.
Choosing when to rely on open source AI
Use open models when you need to run workloads at scale for less, or when compliance demands full control over data flow. They shine in edge deployments where latency is unforgiving. But closed APIs still win for rapid prototyping when your team lacks MLOps depth.
- Score your use cases by latency, privacy, and cost. High sensitivity data tips toward self-hosted open weights.
- Check license terms. Some “open” releases ban commercial use above certain thresholds.
- Model quality matters, but so does the health of the maintainer community. A sparse repo signals future pain.
- Plan for upgrades. Swapping in a new checkpoint should be a routine chore, not a rewrite.
MainKeyword in the stack: open source AI for production
To put open source AI into production, you need steady tooling. Containerize your inference servers, add observability that tracks drift, and set guardrails for prompt injection. Cost models must include GPU rental, networking, and the people who babysit the cluster.
And do not ignore evaluation. Benchmarks tell part of the story, but your domain tests are the ones that keep you honest. I still prefer small synthetic test suites over blind trust in a leaderboard.
Mitigating lock-in if Meta tightens access
If Meta narrows availability, diversify. Keep a secondary model family—Mistral or an open-weight variant of Falcon—ready in your CI. Abstract your model calls behind a service layer so you can swap providers without touching product code. It feels like overkill until a license change lands on a Friday night.
Here’s the thing: governance risk now ranks next to latency and cost. Add it to your risk register and review quarterly.
What to monitor next
Watch for licensing shifts in Llama successors, the strength of community forks, and the GPU pricing curve. New small models that beat Llama on efficiency could change your calculus overnight (I’ve seen teams cut their bill in half by stepping down one size class). Also track how regulators talk about model transparency; policy can nudge giants toward more open releases.
Where to push forward
Start building an A/B path that can run both open weights and closed APIs. Invest in lean evaluation harnesses so you know when a new checkpoint actually helps. The companies that keep optionality will move faster when Meta, or any other giant, shifts course.
Will you wait for the next model drop, or take control of your stack now?