How to Stop LLM Overreliance Before It Costs Your Team
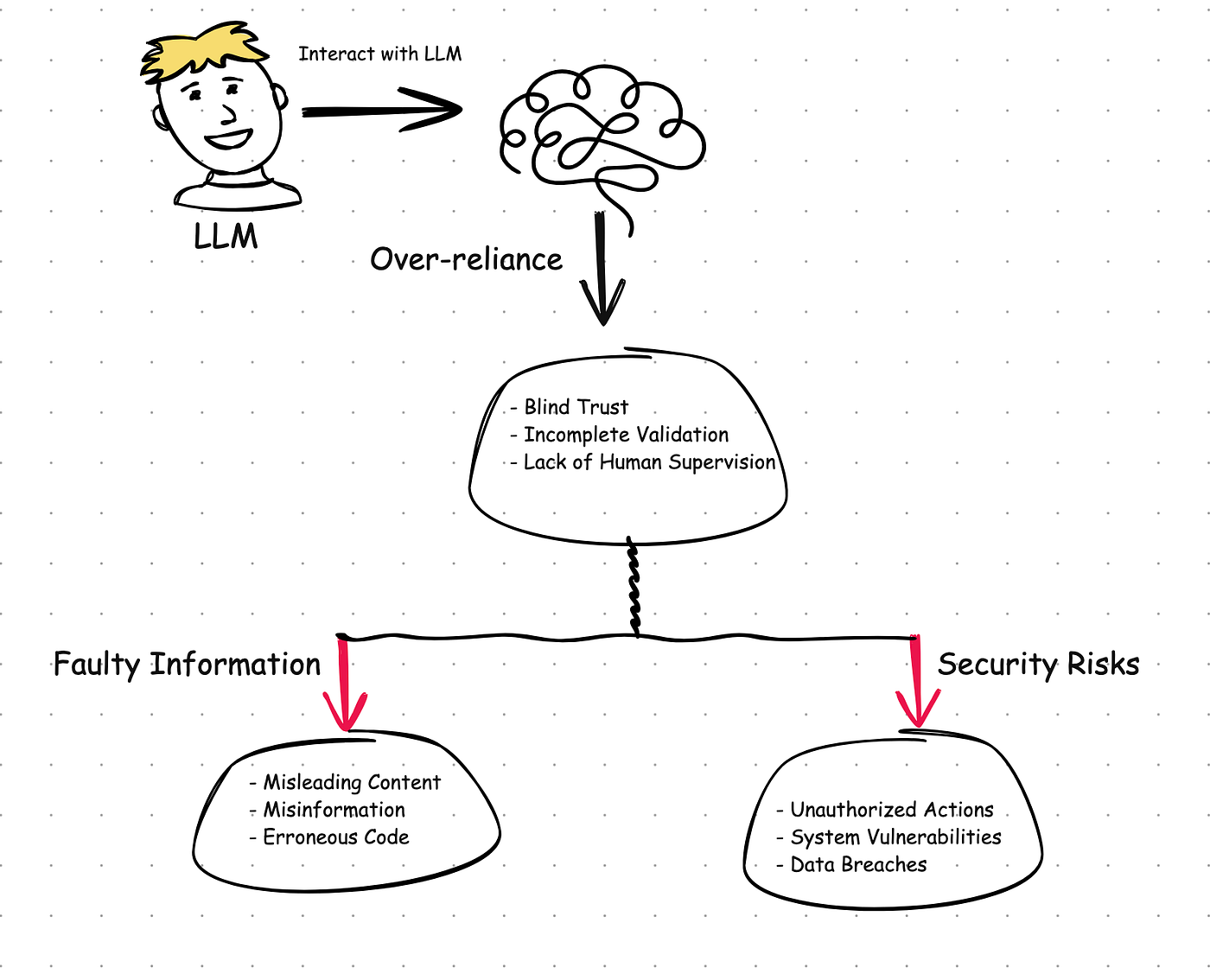
You rushed to ship faster with generative tools, but now you see the side effect: teammates treating the model as the only brain in the room. That is LLM overreliance, and it erodes judgment, quality, and trust. A new study shows how quickly people surrender their own cognition when a chatbot speaks with confidence. The risk is immediate for any team that writes code, drafts docs, or handles customer chats. You still need the speed boost, yet you also need people who think for themselves. Here’s how to keep that balance without slowing down.
What To Watch Right Now
- Design prompts that force verification, not blind acceptance.
- Track when humans override model suggestions to spot drift.
- Rotate critical tasks away from the bot to keep skills fresh.
- Coach teams on when to abandon the tool mid-flow.
Why LLM Overreliance Happens
People trust fluent answers even when they’re wrong. Confidence sounds like competence, so the brain relaxes. Interfaces encourage it with auto-complete and one-click acceptance. That quiet drift toward autopilot is the real risk.
The study found users stuck with the model’s answer even after seeing better human input, a sign that deference sets in fast.
I have watched engineers accept a plausible API call without checking the docs because the model sounded sure. It’s the mental equivalent of letting a treadmill set your pace until you forget how to run outside.
Control LLM Overreliance With Guardrails
Think of this like a basketball coach drilling free throws before letting players shoot from deep. You need reps that build the right habits.
- Force double-checks in the flow. Add a checklist: source link, error path, alt option. Make the form block submission until those fields are filled.
- Require rationale on risky tasks. For security changes or policy text, ask for a two-sentence reason in human words. This slows the reflex to accept.
- Strip passive affordances. Disable one-click insert for critical content; make users copy and paste so they think.
- Set time-boxed reviews. Five-minute spot checks per hour keep people scanning for hallucinations.
Example: Shipping a Support Macro
Before the agent goes live, have a teammate rephrase the answer without the model. If their version reads sharper, use it. If not, at least they tested their own recall. Small friction, big retention.
Metrics That Expose LLM Overreliance
You cannot fix what you cannot see (yes, even seasoned engineers). Track signals that show when minds are switching off. They tell you where to intervene.
- Override rate: How often do humans edit the model output?
- Time-to-first-edit: Does editing drop as trust rises?
- Error source tagging: Are bugs traced to blind acceptance?
- Knowledge check scores: Rotate quick quizzes on recent changes.
Keep the dashboard simple, like lap splits in a race. Speed matters, but so does form.
Policies That Keep Judgment Alive
Policies should feel like rails at a skatepark, guiding without caging. Write them so people know when to lean on the bot and when to park it.
Red lines: No model use for incident comms, legal terms, or personal data replies. Yellow zones: Draft with the bot, but require human validation for anything customer-facing. Green lanes: Use freely for ideation, naming, or refactoring suggestions.
And make ownership explicit. If your name is on the change, you own the validation. That clarity beats any blanket warning.
Training That Beats Passive Usage
Onboarding should model healthy skepticism. Show examples where the model was wrong in subtle ways. Then ask: would you have caught it? That rhetorical question lands harder than any slide deck.
Run drills where the best answer is to discard the model entirely. This is the cognitive equivalent of weight training. You keep the mental muscle from atrophying.
Tools That Encourage Thought
Configure your stack so it nudges good behavior.
- Enable source citations by default and reject outputs without them.
- Show two model answers side by side to force comparison.
- Log prompts and edits so reviewers can see thinking paths.
- Add a “Why trust this?” button that surfaces evidence, not vibes.
Where This Leaves You
LLM overreliance is a creeping problem, not a headline event. The fix is practical: friction in the right spots, visibility into drift, and training that prizes judgment. Keep the tool, keep the speed, but keep your team’s brain in the loop. How else will you spot the next bad answer before it ships?


