Amazon EKS AMI Updates with GitOps
Keeping worker nodes current in Kubernetes is one of those jobs that sounds routine until it breaks something. You need fresh security patches, stable node images, and a process your team can trust under pressure. That is why Amazon EKS AMI updates with GitOps matter right now. AWS is pushing a pattern that ties event-driven automation, Amazon EKS managed node groups, GitOps workflows, and AI-assisted review into one update loop. The pitch is simple. Detect a new EKS-optimized AMI, open a pull request, review the change, then let GitOps apply it. For platform teams, that can cut manual toil and reduce image drift. But the real value is not the AI label. It is the fact that the whole chain becomes visible, auditable, and easier to roll back when things get weird.
What this setup gets right
- It turns AMI tracking into an event-driven workflow, instead of a calendar reminder someone forgets.
- Git stays the control point, which means approvals, history, and rollback remain intact.
- AI is used as a helper, not as the final authority on infrastructure changes.
- It fits existing AWS tools such as EventBridge, Lambda, CodeCommit or GitHub-style repos, and Argo CD or Flux.
How Amazon EKS AMI updates with GitOps work
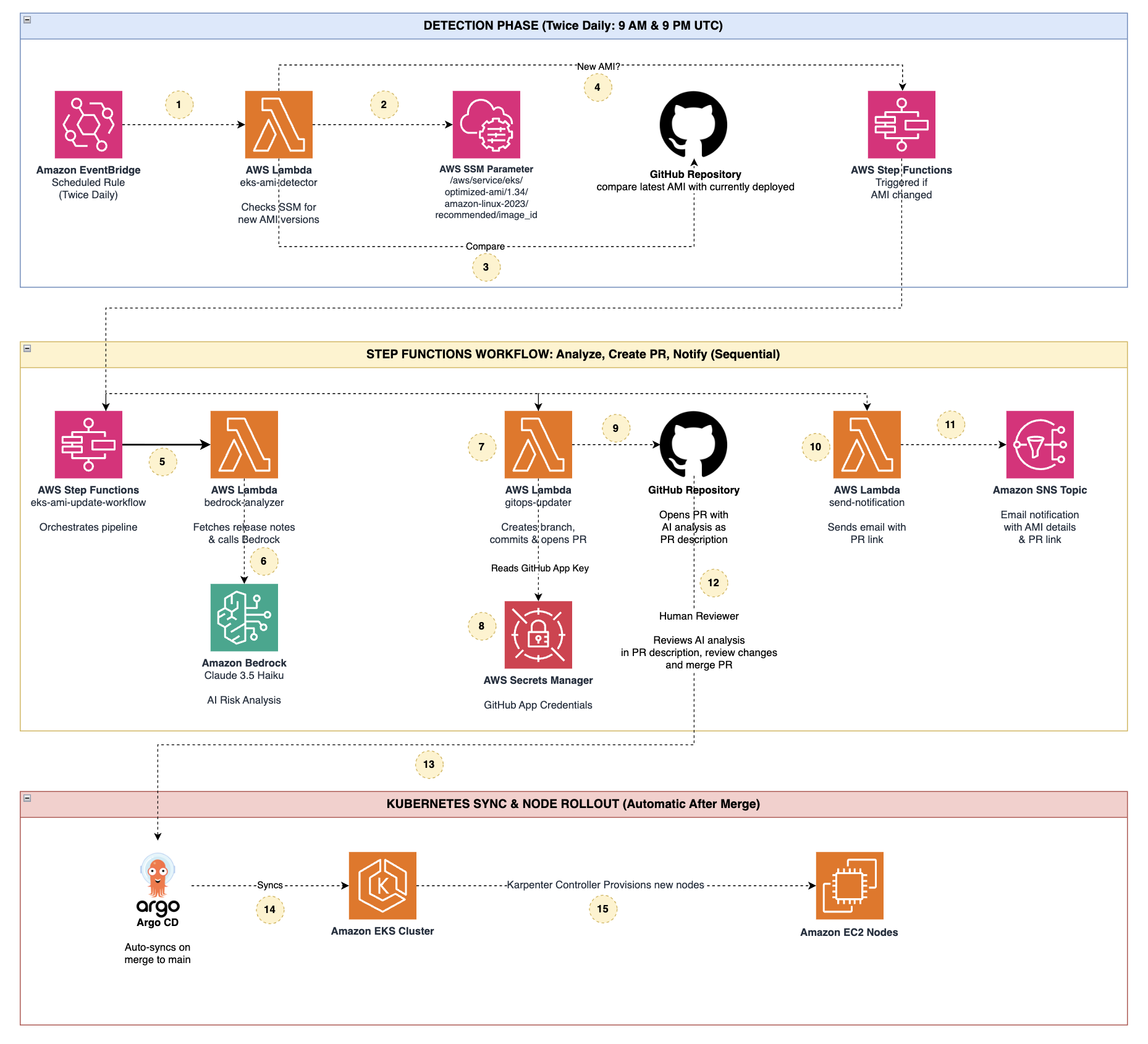
The AWS pattern starts with a new Amazon EKS optimized AMI release. That release becomes the trigger for the rest of the pipeline. Instead of waiting for an operator to notice the update, an event-driven flow picks it up and starts the change process.
From there, automation updates the infrastructure code that defines the node group AMI or launch template version. The system then creates a pull request in your Git repository. If you use GitOps the right way, that repository is the source of truth for the cluster.
That part matters.
Once the pull request is approved and merged, your GitOps controller applies the change to the cluster. In practice, that usually means Argo CD or Flux reconciling the desired state, followed by a managed rollout of nodes in Amazon EKS. The node refresh happens through standard AWS mechanics, not through a mystery box.
Good platform automation does not remove review. It moves review to the place where teams already make infrastructure decisions, which is Git.
Why AWS adds AI to the Amazon EKS AMI updates with GitOps flow
AWS frames this as an AI-powered approach, but look closely and the AI role is narrower than the headline suggests. The AI component helps summarize the AMI change, explain release details, and support faster review of the pull request. That can save time, especially for teams managing several clusters across accounts.
And that is useful. But it is not magic.
The strongest part of the design is still the event-driven GitOps pipeline. AI helps humans make faster calls. It does not replace testing, staged rollouts, Pod Disruption Budgets, or sane maintenance windows. Anyone telling you otherwise is selling theater.
Think of it like a good sous-chef in a busy kitchen. Prep gets faster, notes are clearer, and the head chef wastes less time. But the chef still decides what leaves the pass.
Core building blocks in the AWS design
Event detection
The flow uses AWS event-driven services to react when a new EKS AMI becomes available. In AWS architectures like this, Amazon EventBridge is often the glue because it can route events with very little friction.
Automation layer
AWS uses compute logic, commonly AWS Lambda, to parse the event, identify the target version, and update the Git-backed configuration. That function can also call an AI service to generate a summary for reviewers (for example, what changed and which clusters may be affected).
Git repository and pull requests
The configuration change lands in Git as a proposed edit. Reviewers can inspect the AMI version bump, compare it against cluster version constraints, and decide whether to approve. That is a clean fit for infrastructure as code.
GitOps reconciliation
After merge, a GitOps controller like Argo CD or Flux applies the change. This preserves a traceable path from event to rollout. If a node image causes trouble, rollback is far less painful because the desired state is versioned.
What problems this pattern actually solves
- Patch lag
Teams often delay AMI updates because the process is manual and easy to postpone. Event-driven triggers remove that excuse. - Configuration drift
Manual updates done in the console create drift between the cluster and the repo. GitOps closes that gap. - Review fatigue
AI-generated summaries can give reviewers quicker context, which helps when every infra PR starts to look the same. - Audit pressure
Regulated teams need proof of who approved what. Git-based workflows make that record plain.
Where teams should be careful
Here is the thing. Updating an AMI is never just an AMI update. It can touch kernel behavior, container runtime details, bootstrap settings, and add-on compatibility. If you run EBS CSI, VPC CNI, Karpenter, NVIDIA drivers, or custom launch templates, you need more than an auto-generated summary.
So build guardrails around the workflow:
- Test new AMIs in a non-production EKS cluster first.
- Use progressive rollout patterns across environments.
- Confirm node draining and workload disruption policies are sane.
- Track application SLOs during the node group update.
- Keep rollback steps documented in the same repo.
A flashy pipeline that pushes bad images faster is still a bad pipeline.
Practical advice for platform teams
If you want to copy this pattern, start with the boring parts. Define where AMI versions live in Git. Decide who approves pull requests. Set rules for staging, production, and emergency patch paths. Then add the event trigger and AI helper last.
Honestly, many teams should treat AI as optional in phase one. The event-driven GitOps model already brings most of the value. Once that foundation is stable, AI summaries can shave review time and help junior operators understand why a change showed up.
A solid rollout plan usually includes these steps:
- Store EKS node group or launch template settings in Git.
- Automate detection of new EKS optimized AMIs.
- Create pull requests with the exact version change.
- Run validation checks, including policy and integration tests.
- Require human approval for production environments.
- Let Argo CD or Flux apply the merged change.
- Watch rollout metrics and keep a fast rollback path.
What the AWS post signals about the market
AWS is not just showing off a tidy automation demo. It is signaling where cloud operations are headed. Infrastructure updates are becoming event-driven, repo-centered, and AI-assisted in small but practical ways.
Will every team need this exact stack? No. Smaller shops may be fine with scheduled reviews and manual PRs. But larger EKS estates, especially those spread across regions and business units, will feel the pull. The bigger the fleet, the less tolerance you have for ad hoc node maintenance.
(And yes, this also helps platform teams justify standardization around GitOps.)
The real test
The smartest way to judge Amazon EKS AMI updates with GitOps is simple. Ask whether it makes your cluster updates safer, faster, and easier to explain to another engineer at 2 a.m. If the answer is yes, keep going. If the answer is no, the AI wrapper is beside the point.
AWS has the right instinct here. Tie infrastructure changes to events, route them through Git, and let machines do the repetitive parts. The next question is the one that matters for your team. How much of that update path are you still handling by hand?


