Anthropic Claude Guardrails and Invisible Distillation
If you use Claude for work, you probably care about speed, quality, and whether the model stays within the lines. That last part matters more now. Anthropic Claude guardrails are no longer a side issue, because the company is facing a sharper fight over model misuse, invisible distillation, and the limits of polite safety layers.
Why should you care? Because the same systems that make Claude useful for writing, coding, and analysis also make it tempting for other companies to copy behavior without permission. That creates a messy incentive structure. It affects product trust, licensing, and how much control a model maker really has once its outputs are out in the wild. And yes, this is the part the hype crowd tends to skip.
- Anthropic Claude guardrails are becoming part of the product story, not just the safety story.
- Invisible distillation raises questions about how model behavior gets copied without a clean paper trail.
- Better safety controls can reduce abuse, but they do not stop every form of extraction.
- Model makers now have to think like platform operators, not just researchers.
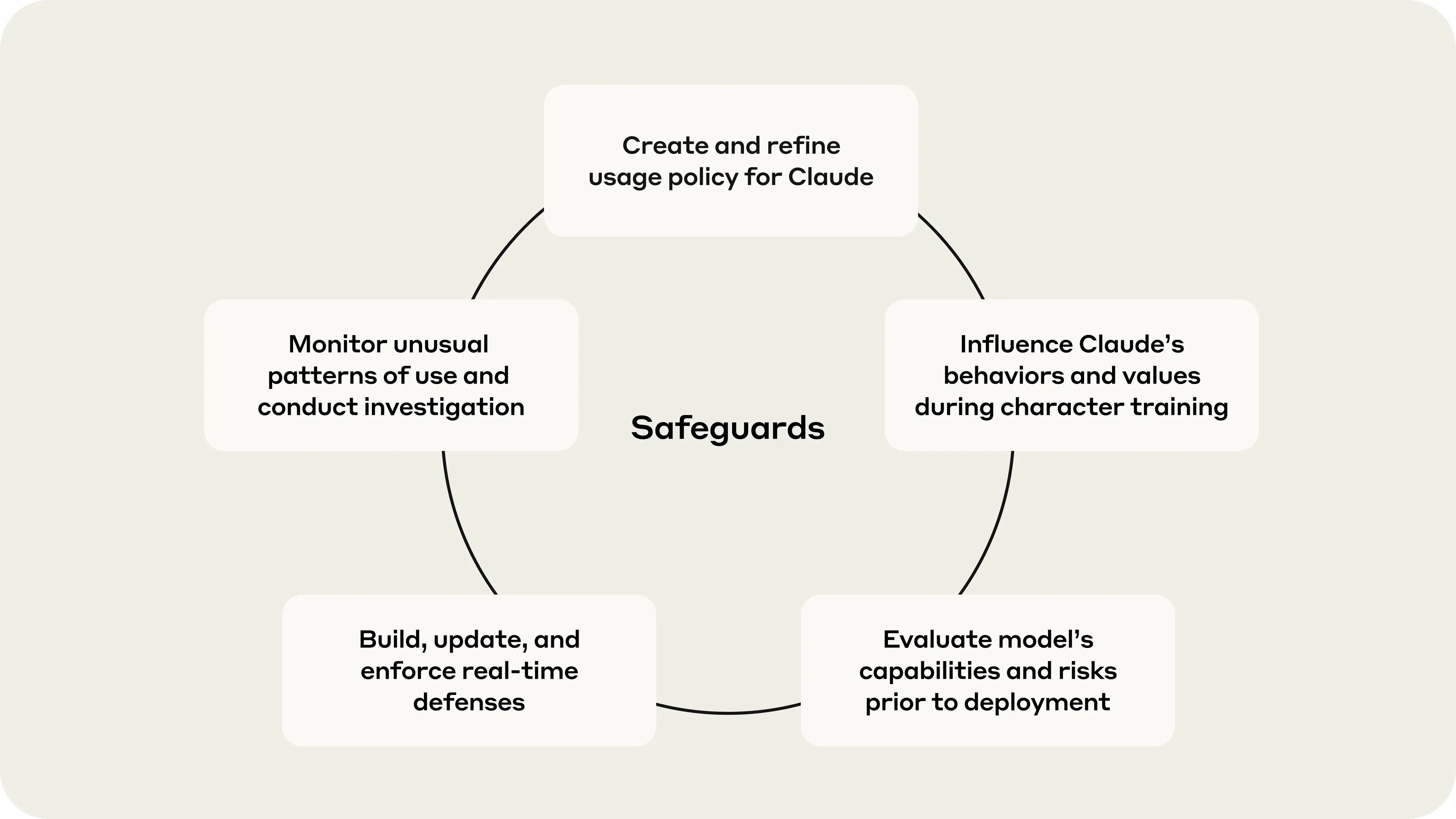
What are Anthropic Claude guardrails really for?
Anthropic has always sold Claude as a careful model. The company leans on policy filters, refusal behavior, and other control layers to keep the system from drifting into risky outputs. That sounds tidy on paper. In practice, it is closer to a security system for a busy office building. It slows some bad behavior, but it cannot stop someone from walking around the side entrance.
The point of Anthropic Claude guardrails is simple. They are meant to reduce harmful output, limit misuse, and shape how the model responds under pressure. They also help Anthropic protect its brand. If Claude starts sounding careless, users notice fast.
Safety features are useful, but they are not a moat by themselves. If a model can be queried at scale, its behavior can be studied at scale too.
Why invisible distillation is the bigger problem
Invisible distillation is the ugly phrase hiding behind a very practical tactic. A company can use another model’s responses as training material, then build a rival system that imitates the original without openly licensing it. That is not the same as copying weights. But the effect can still be serious. It can strip value from the original model provider while making enforcement harder.
Here is the thing. If you can query a model and collect enough high-quality answers, you may not need the source model itself. You can train on the behavior. You can train on the style. You can even train on its refusal patterns. That is where the pressure lands on Anthropic and every other frontier lab.
And this is not just a legal headache. It changes product strategy. If outputs can be harvested cheaply, then guardrails must do double duty. They need to protect users and make extraction less attractive.
How Claude guardrails fit into the business fight
Anthropic is competing in a market where product features, pricing, and safety claims all blur together. Strong guardrails can attract enterprise buyers who do not want embarrassing policy slips. They can also frustrate some users who want fewer refusals. That tradeoff is real. You cannot pretend otherwise.
Think of it like building a kitchen that only lets approved recipes through. Great for food safety. Annoying if you are trying to experiment. The balance matters, because buyers often ask for the same thing in different words: give me freedom, but do not let me get burned.
- Enterprise buyers want predictable outputs and lower compliance risk.
- Developers want fewer false refusals and cleaner APIs.
- Anthropic wants both, while also limiting copycat behavior.
Does stronger safety hurt model usefulness?
Sometimes. If guardrails are too aggressive, the model gets timid. It refuses normal requests, hedges too much, or produces bland answers. But weak guardrails create their own mess. Users hit dangerous outputs, and the company absorbs the fallout. Which failure mode is worse? That depends on your use case, but there is no free lunch here.
Anthropic has to tune Claude so it stays helpful without becoming easy to abuse. That is a narrow path, and every adjustment changes the feel of the product. Anyone who has used large language models for real work knows how quickly trust can evaporate after one off response.
What this means for the AI market
The Claude story is bigger than one model. It shows where the market is heading. Model makers are now defending not only against misuse, but also against mimicry. That means more attention on logging, rate limits, policy enforcement, and output controls. It also means more tension between openness and protection.
Regulators will be watching this too. If invisible distillation becomes a standard tactic, then the legal questions around model output, training data, and competition law get louder. The industry has spent years acting like behavior is too fuzzy to police. That excuse is wearing thin.
Anthropic Claude guardrails may help Anthropic keep some control, but they will not solve the core problem on their own. The real test is whether companies can make models useful enough for serious work while making mass extraction expensive and unreliable. That is the line everyone is chasing now.
What you should watch next
Keep an eye on how Anthropic changes Claude’s refusal behavior, API controls, and enterprise terms. Those details tell you more than the marketing copy does. They show whether the company is tightening the screws or just talking a better safety game.
Also watch how rivals respond. If one lab gets serious about guardrails and anti-distillation defenses, others will have to follow or risk becoming training data for the next competitor. That is the race now. Who can stay useful, trusted, and hard to copy?
Not a small question. Not anymore.


