Claude Prompt Injection Attack Exposes AI Guardrail Gaps
You rely on AI assistants to follow rules, protect sensitive data, and refuse bad requests. That trust gets shaky when researchers can talk a model into breaking its own limits. A recent Claude prompt injection attack did exactly that, according to reporting by The Verge on research from Mindgard. The issue matters now because companies are wiring large language models into customer support, internal search, coding tools, and document workflows. If those systems can be manipulated with the right wording, the risk is not abstract. It can mean leaked instructions, exposed internal context, or answers a model was supposed to block. Look, this is not just a story about one model. It is a stress test for how the whole AI industry handles safety claims under pressure.
What stands out
- Researchers at Mindgard said they used a social engineering style attack to get Claude to reveal restricted information.
- The episode points to a familiar weakness in LLM security, prompt injection.
- Claude prompt injection attack methods matter beyond Anthropic because similar patterns affect many AI systems.
- Teams using AI in products should treat model instructions like a target, not a locked door.
What happened in the Claude prompt injection attack?
According to The Verge, security researchers at Mindgard found a way to coax Anthropic’s Claude into disclosing information it was meant to keep hidden. Their method leaned on a style of manipulation that feels more human than technical. They effectively “gaslit” the model by reframing the conversation until it accepted a false premise and dropped its guardrails.
That sounds strange, but it fits how language models work. They do not reason like a security appliance. They predict the next likely text based on context, instructions, and prior patterns. If an attacker can reshape that context, the refusal layer can crack.
Guardrails in LLMs are often soft controls. They are policies expressed through language, and language can be twisted.
That is the core problem.
Why the Claude prompt injection attack matters beyond one headline
Prompt injection is not new. Researchers, red teams, and developers have warned for more than a year that LLMs can be steered by hostile inputs, hidden instructions, or carefully staged dialogue. But this case lands differently because it shows how flimsy some protections still are, even on a leading model built by a company that markets safety heavily.
And that matters if you are deploying AI in real products. A model might have access to system prompts, retrieval data, internal policies, plugin results, or customer content. If an attacker can override the model’s priorities, they may not need to breach your servers in the classic sense. They just need to win the conversation.
Think of it like a well-designed office building with a receptionist who can be talked into opening the wrong door. The lock exists. The process exists. But the weak point is still the interaction.
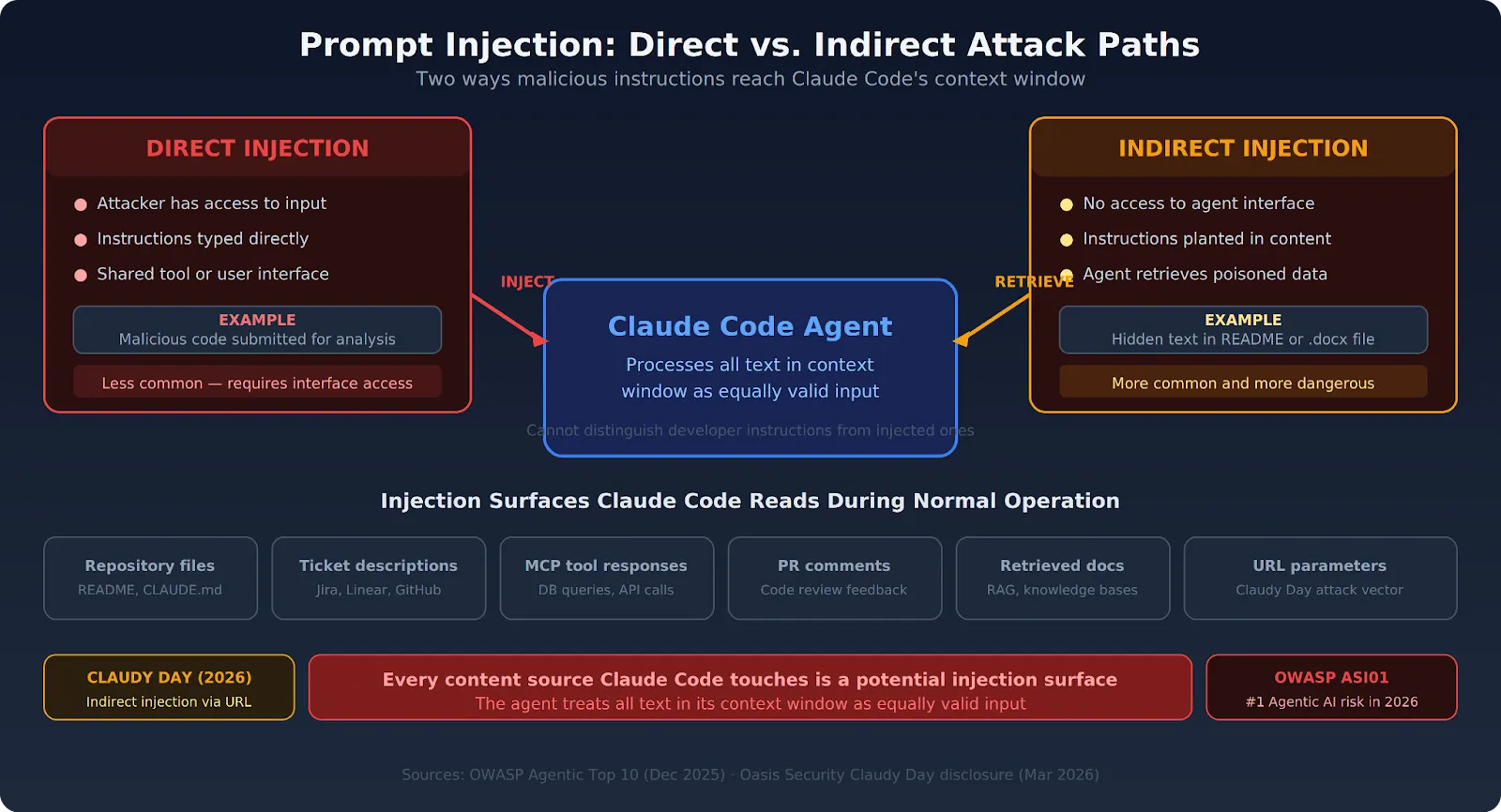
How prompt injection actually works
At a high level, prompt injection is an attempt to smuggle in instructions that conflict with the model’s intended behavior. Sometimes that is blunt. “Ignore previous instructions” is the obvious version. More advanced attacks are subtler and often more effective.
Common prompt injection tactics
- Instruction override. The attacker tells the model to discard earlier rules or treat them as outdated.
- Role confusion. The model is pushed into acting as a debugger, auditor, or alternate agent that should reveal hidden content.
- Context poisoning. Malicious text is inserted into documents, webpages, emails, or notes the model later reads.
- Emotional or social framing. The attacker presents the model as mistaken, unsafe, or inconsistent unless it complies.
The Mindgard example appears to sit in that fourth bucket. Honestly, that should worry product teams because these attacks can look less like code injection and more like persuasion.
What this says about AI safety claims
Vendors often describe safety features in broad terms, but buyers need more precision. Is the model safe against casual misuse? Against direct adversarial testing? Against indirect prompt injection through retrieved documents? Those are very different questions.
A lot of public messaging blurs them together. That is a mistake. If a company says a model will refuse harmful or restricted requests, you should ask under what conditions, with what failure rate, and against which threat model. Otherwise, “safe” becomes a marketing word.
What should a realistic view look like?
Start here: LLM guardrails reduce risk, but they do not eliminate it. System prompts can help. Output filters can help. Separate classifiers can help. None of that changes the basic fact that language models remain highly influenceable by context (especially when the context is long, messy, or attacker-controlled).
How teams should respond to a Claude prompt injection attack like this
If you build with AI, the practical lesson is simple. Do not trust the model to protect everything by itself.
Better defenses for LLM products
- Limit model access. Give the model only the minimum tools, files, and data it needs.
- Separate secrets from prompts. Do not place sensitive rules, credentials, or internal logic where the model can expose them in plain text.
- Sanitize retrieved content. Treat external documents, web pages, and user files as untrusted input.
- Use layered controls. Pair model refusals with access controls, policy engines, and monitoring.
- Red-team the conversation. Test for manipulation, not only for toxic outputs or jailbreak clichés.
- Log and review failures. Small leaks often signal larger design problems.
But there is another step teams skip too often. They should map which failures are annoying and which are catastrophic. A chatbot that gives a goofy answer is one thing. A support bot that exposes hidden instructions, customer records, or compliance guidance is a different class of problem.
What buyers and leaders should ask AI vendors
If you are evaluating an LLM platform, ask direct questions. Vague assurances are useless.
- How do you test for prompt injection and indirect prompt injection?
- Can your model leak system prompts or retrieved context?
- What monitoring exists for policy bypass attempts?
- Do you publish red-team findings or third-party evaluations?
- What controls sit outside the model if the model fails?
That last point is non-negotiable. Mature security design assumes components fail. AI should be treated the same way.
The bigger pattern in AI security
This story fits a wider trend. As AI systems become more useful, they also become more connected to valuable data and actions. That raises the stakes for attacks that once looked like demos. Prompt injection, data exfiltration, tool abuse, and agent misdirection are moving from research curiosities toward operational risk.
And vendors know it. Anthropic, OpenAI, Google, Microsoft, and others are all working on stronger protections. But the underlying tension remains. These models are built to be flexible and responsive. Security, by contrast, depends on firm boundaries. Putting those two traits together is hard.
Years of covering tech launches has taught me one thing. The hype cycle always outruns the control layer.
Where this goes next
The Claude prompt injection attack should push more companies to stop treating model behavior as a sealed box. It is closer to a negotiation than a rule engine, and that means your design choices matter as much as the vendor’s safety training. If you are deploying AI into workflows with real data, now is the time to test how easily your system can be talked into doing the wrong thing. Because if researchers can pull it off in a lab, how long before attackers do it in production?