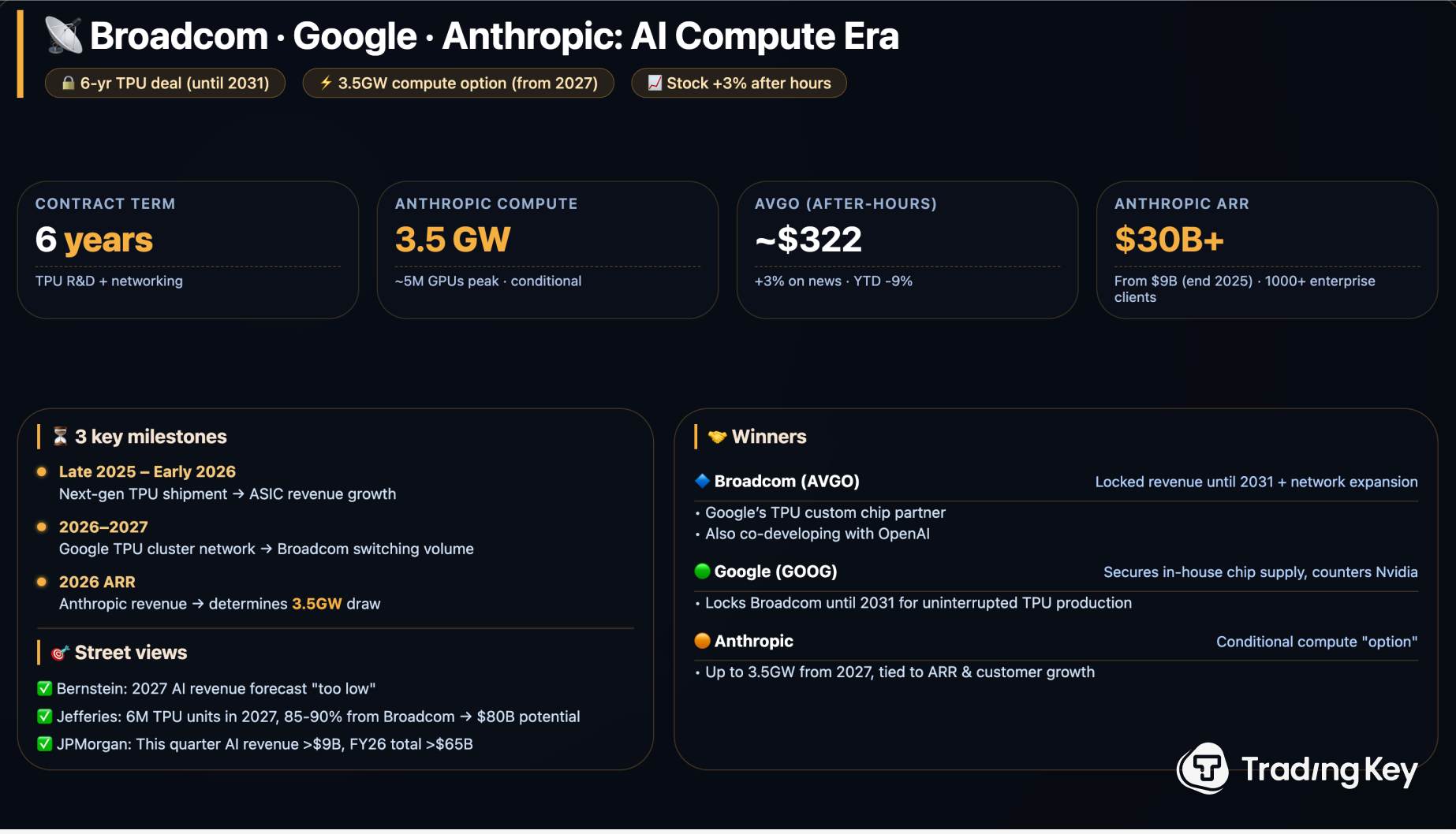
Anthropic’s TPU Compute Play with Google and Broadcom: What Teams Need to Know
AI builders are hunting for dependable compute and the Anthropic TPU compute deal finally shows a path that blends scale with predictable pricing. The agreement between Anthropic, Google, and Broadcom signals that Claude’s growth will lean on custom tensor processing units instead of general GPUs, and that matters for every team budgeting for inference. If you rely on foundation models, your spend and latency live or die by the hardware stack. This Anthropic TPU compute deal arrives as GPU queues stretch, cloud bills spike, and compliance teams want location clarity. Do you keep chasing scarce GPUs or pivot to a TPU-first roadmap? The answer shapes your roadmap for the rest of the year.
Rapid Takeaways
- Anthropic gains dedicated Google Cloud TPU capacity, cutting GPU exposure and queue risk.
- Broadcom’s custom silicon role hints at tighter cost controls and faster iteration.
- Customers should expect clearer latency profiles and potential price stability.
- Multi-cloud remains limited; lock-in risk is real but manageable.
How the Anthropic TPU Compute Deal Changes Capacity Planning
Think of TPUs as a purpose-built kitchen line instead of a shared buffet: every station designed for one menu reduces chaos and speeds plates. Dedicated TPU access means Anthropic can forecast throughput and batch sizes with fewer surprises, which should reduce the variance you feel in latency-sensitive workloads. Here’s the thing: stability beats peak speed when you are shipping user-facing features.
“Predictable capacity is the new currency for AI teams trying to ship on time,” a cloud architect told me recently.
This is also a hedge against the GPU shortage cycle. When Broadcom supplies custom components, Google can tune boards and networking for Anthropic’s models instead of playing catch-up with general-purpose demand.
Where Anthropic TPU Compute Deal Fits Your Cost Strategy
Prices have not been announced in detail, but the structure points to steadier per-token costs. You should model scenarios with fixed TPU pricing bands and compare them to spot GPU volatility. Ask yourself a blunt question: will steady but slightly higher base rates beat the risk of throttled GPU access during peak traffic?
Practical steps to capture savings
- Benchmark Claude on TPU-backed endpoints and log token-level latency and error rates for two weeks.
- Shift batch inference or overnight fine-tunes to TPU windows where rates are lower.
- Negotiate committed use discounts that tie volume to TPU reservations, not generic GPU pools.
Single-sentence warning: do not ignore egress costs when routing results to another cloud.
Risk Checks: Lock-In, Geography, and Compliance
Anthropic’s dependence on Google Cloud TPUs limits multi-region flexibility today, though Google’s footprint is wide enough for most regulated workloads. If your governance rules need data residency, press for region lists and failover plans (backups across two TPU regions mimic double-pan cooking in a busy restaurant). But what happens if TPU supply tightens? Keep a slim GPU fallback, even if it runs at lower batch sizes, to maintain uptime.
Deployment Playbook for Teams Adopting TPUs
Rollouts work best in phases. Start with staging traffic on TPU-backed endpoints and record P99 latency. Graduate to user cohorts once error rates stabilize. And yes, run shadow tests comparing GPU and TPU responses for drift. The bursty sentence rhythm mirrors the operational reality: test, pause, adjust.
- Observability: add TPU-specific metrics for queue depth and HBM utilization.
- SLAs: rewrite contracts to reflect TPU availability clauses.
- Failover: script automatic reroutes to GPU paths if TPU queues exceed thresholds.
Look, resilience beats elegance when you are on the hook for uptime.
What This Signals for the AI Infrastructure Market
Google secures a marquee customer, Broadcom lands a steady silicon pipeline, and Anthropic gains leverage over GPU price swings. This triangulation shows that vertical integration is back in style. The analogy to a sports team fits: the best clubs own their training grounds and tailor them to their playbook instead of renting public fields.
Will other model vendors strike similar hardware-first deals? That is the open question that will shape 2026 pricing battles.
Next Moves for Builders
If you are planning Q3 feature launches, block off time to run TPU pilots now. Update your cost calculators, renegotiate enterprise clauses with TPU metrics included, and brief support teams on expected latency changes. I would bet that teams who secure TPU-backed commitments early will ride out the next GPU squeeze with calmer dashboards.