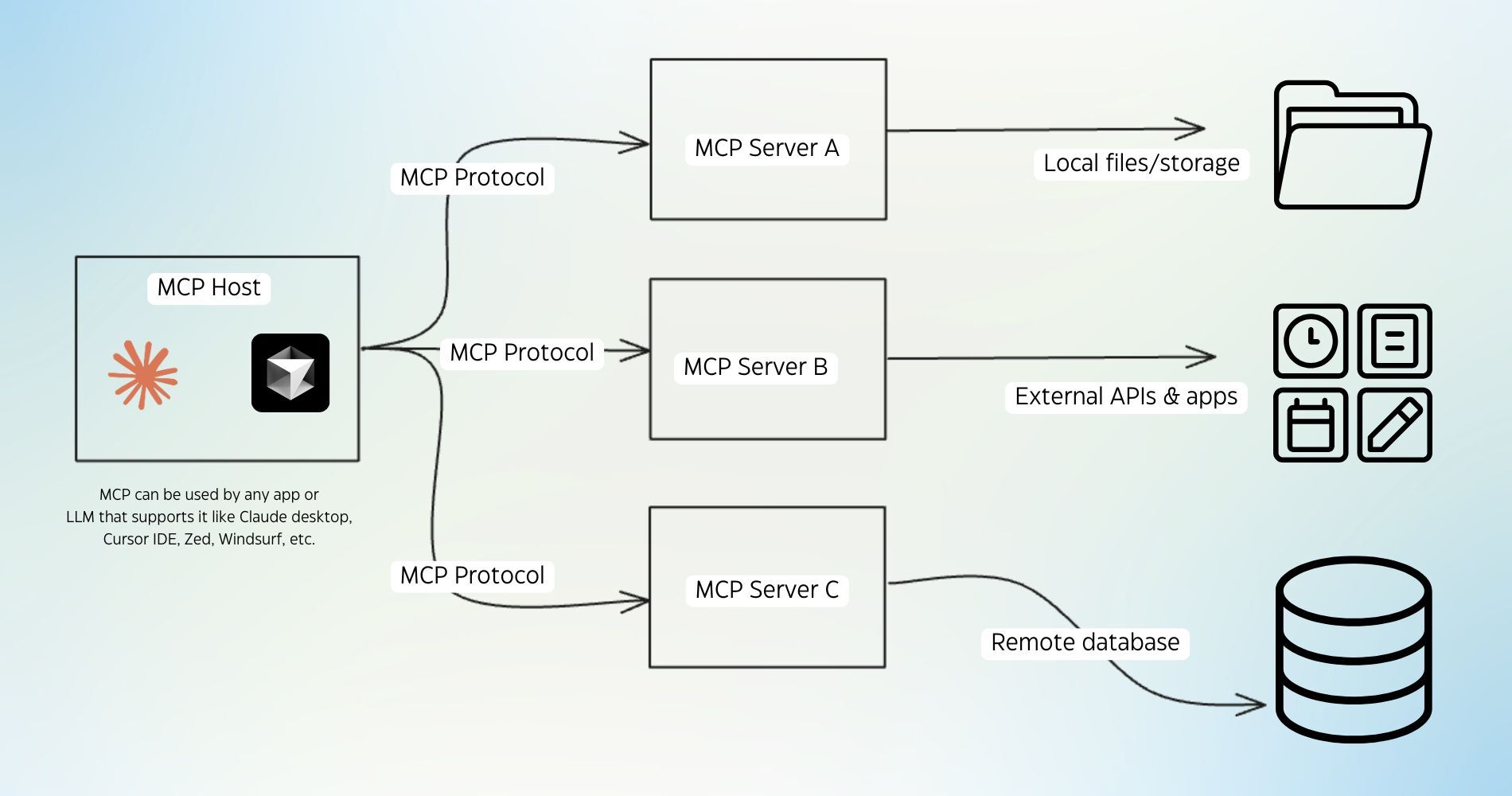
ScaleOps and the new playbook for Kubernetes cost optimization
Kubernetes cost optimization just jumped from back-office chore to board-level mandate. ScaleOps raised $130 million in Series C funding as AI demand spikes cluster usage, and that cash signals that the market wants sharper control over cloud bills right now. You feel the pressure because every GPU minute and pod restart shows up in the CFO’s slide deck. The promise is clear: reclaim spend without slowing delivery. The risk is just as obvious: blunt cuts that throttle AI services. Here’s how to thread that needle while the funding spotlight stays hot.
Rapid highlights for busy teams
- ScaleOps’ fresh $130M fuels automation that rightsizes Kubernetes in real time.
- AI workloads amplify cost drift; proactive policies beat reactive fire drills.
- Unit economics per service reveal where to trim without breaking SLAs.
- Platform teams need SLOs for both reliability and spend, not one or the other.
Why Kubernetes cost optimization matters in AI-heavy stacks
Look, AI inference and training workloads turn cluster costs into a moving target. GPU nodes sit idle between jobs, autoscalers overreact, and background services sprawl. It feels like leaving stadium lights on after the game. The market move by ScaleOps shows investors expect tooling that clamps down on that waste without slowing model delivery. Do you really know which namespace is burning the budget today?
One-sentence clarity.
How ScaleOps positions its Series C as a signal
The company frames the raise as fuel for more automation and policy depth. More capital means faster feature rollout: predictive scaling, smarter bin packing, and spend-aware scheduling. That aligns with what enterprise buyers keep asking for: savings they can verify, plus guardrails that keep developers shipping. The real test is whether the platform can integrate into existing observability and CI pipelines instead of adding yet another dashboard.
“Savings only stick when developers see them in their workflow, not after the monthly bill shock,” said one platform lead I spoke with last quarter.
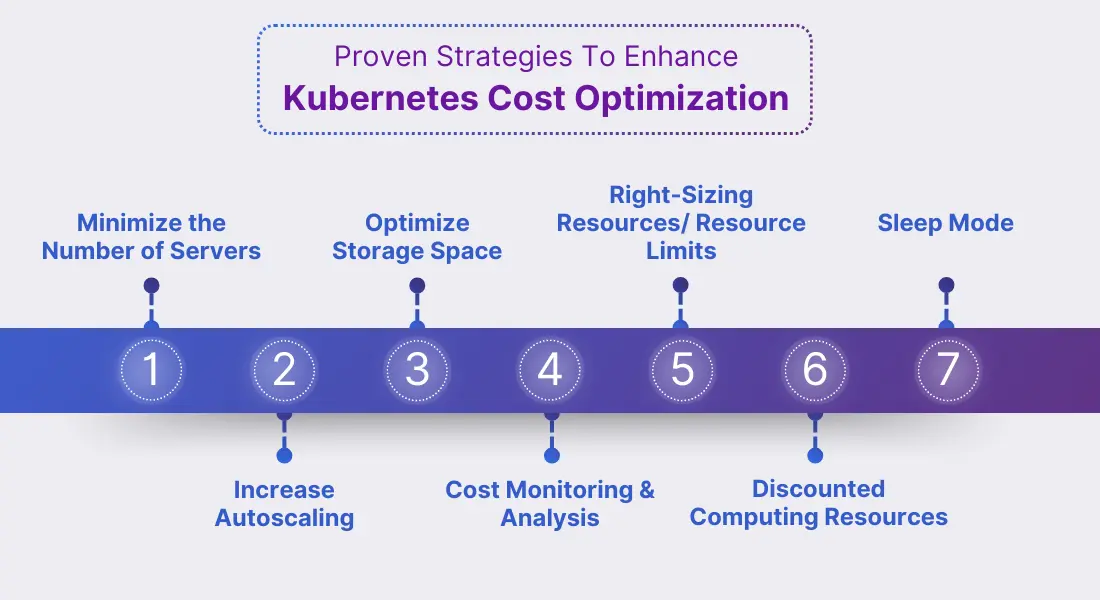
Kubernetes cost optimization tactics you can deploy now
- Tag everything: Enforce labels by namespace and team. Cost data without ownership is noise.
- Set SLOs for spend: Add budget SLOs alongside latency SLOs. Breach alerts drive action before invoices do.
- Rightsize with data: Use vertical pod autoscaling suggestions during off-hours rollouts. Start with non-critical services to build trust.
- Schedule AI jobs: Batch training at low-traffic hours. Think of it like running laundry at night to avoid peak rates.
- Adopt pod disruption budgets wisely: Prevent thrash when nodes drain, but keep them loose enough to allow bin packing.
Integrating mainKeyword into platform workflows
Kubernetes cost optimization only sticks when platform teams wire it into day-to-day habits. Pipe cost metrics into code reviews so engineers see the delta from resource requests. Add cost checks to admission controllers. Pair this with a change calendar that highlights high-cost deployments. The goal is to make spend visible at the same moment someone ships code.
Observability that respects developers
Overloading teams with dashboards backfires. Instead, surface one metric per service: cost per request or cost per thousand tokens for AI endpoints. That keeps debates grounded in unit economics. It mirrors a sports coach showing shot charts instead of raw possession time.
Risks and trade-offs teams ignore
Cutting resources too fast can inflate tail latency and trigger retries that cost even more. Spot instances save cash but introduce interruption risk that some AI jobs cannot absorb. There is also cultural drag: developers may see cost controls as friction unless leadership links savings to reinvestment in tooling. Balance matters.
What ScaleOps must prove next
The funding headline is flashy, but execution is the metric. Can ScaleOps plug into existing OpenTelemetry setups? Will it surface per-team budgets without forcing migration from current CI systems? And how does it handle multi-cloud clusters where pricing models differ? Those answers will decide if this round creates a new category leader or just another tool in the drawer.
Where to start this quarter
- Pick three services with the highest idle allocation and pilot autoscaling tweaks.
- Define budget SLOs per team and connect alerts to chat, not email.
- Review GPU node utilization weekly with product owners present.
- Document a rollback path for any cost policy so developers stay confident.
Looking ahead
AI demand is not slowing, and neither are cloud bills. The teams that win will treat Kubernetes cost optimization as product work, not finance admin. Expect more capital to chase this space, and expect your board to ask sharper questions about spend. Are you ready to answer with data and a plan?